I used reminders extensively in Inbox. Inbox is going away (end of March 2019). Google calendar has a notion of a reminder, but you can't get email notifications of those, so there's no way to keep track of which reminders you haven't done yet. However, calendar events do have email notifications you can enable. That seems close enough. Below is the python code I used to transfer over my reminders, both current and future, to calendar events or email.
The code below has some extra info on the undocumented Google api for searching and deleting reminders as well. Note you need to get an API key before using this code (see below)
#!/usr/bin/python3 -t
import re
import argparse
import json
import os
import readline # to enable navigating through entered text
import time
import copy
from typing import Tuple
#from email import encoders
import base64
from email.mime.text import MIMEText
import httplib2
from oauth2client import tools
from oauth2client.client import OAuth2WebServerFlow
from oauth2client.file import Storage
import datetime #from datetime import datetime, timezone
import dateutil.tz
USER_OAUTH_DATA_FILE = os.path.expanduser('tmp/google-reminders-cli-oauth')
def authenticate() -> httplib2.Http:
# You need a Google project and credentials. Check out
# https://console.cloud.google.com/apis/credentials
app_keys = {
"APP_CLIENT_ID": blah,
"APP_CLIENT_SECRET": moreblah
}
storage = Storage(USER_OAUTH_DATA_FILE)
credentials = storage.get()
if credentials is None or credentials.invalid:
credentials = tools.run_flow(
OAuth2WebServerFlow(
client_id=app_keys['APP_CLIENT_ID'],
client_secret=app_keys['APP_CLIENT_SECRET'],
scope=['https://www.googleapis.com/auth/reminders',
'https://www.googleapis.com/auth/calendar.readonly',
'https://www.googleapis.com/auth/calendar.events',
'https://www.googleapis.com/auth/gmail.insert',
'https://www.googleapis.com/auth/userinfo.email',
'https://www.googleapis.com/auth/gmail.labels',
],
user_agent='google reminders cli tool'),
storage,
)
auth_http = credentials.authorize(httplib2.Http())
return auth_http
calendarVersion = "WRP / /WebCalendar/calendar_190310.14_p4"
reminderHeaders = {
'content-type': 'application/json+protobuf',
}
def printReminder(auth_http, aReminderId):
request = {"1":{"4":calendarVersion},"2":[{"2":aReminderId}]}
response, content = auth_http.request(
uri='https://reminders-pa.clients6.google.com/v1internalOP/reminders/get',
method='POST',
body=json.dumps(request),
headers=reminderHeaders,
)
assert(response.status == 200)
obj = json.loads(content)
print(obj)
def main():
auth_http = authenticate()
# https://developers.google.com/oauthplayground/ for figuring out scopes and apis using the scopes
response, content = auth_http.request(
uri='https://www.googleapis.com/userinfo/v2/me',
method='GET',
headers={'content-type': 'application/json'},
)
assert response.status == 200, (response, content)
obj = json.loads(content)
email = obj['email']
print('Got email', email)
jreminderLabelId = None
if not jreminderLabelId:
response, content = auth_http.request(
uri='https://www.googleapis.com/gmail/v1/users/me/labels',
method='GET',
headers={}, #'content-type': 'application/json'},
)
assert(response.status == 200)
obj = json.loads(content)
labels = obj["labels"]
jreminderLabelId = None
for labelInfo in labels:
if labelInfo["name"] == "jreminder":
jreminderLabelId = labelInfo["id"]
break
assert jreminderLabelId
print('Got jreminder label id', jreminderLabelId)
reminderCalendarId = None
if not reminderCalendarId:
response, content = auth_http.request(
uri='https://www.googleapis.com/calendar/v3/users/me/calendarList',
method='GET',
headers={}, #'content-type': 'application/json'},
)
assert(response.status == 200)
obj = json.loads(content)
calendars = obj["items"]
for aCal in calendars:
#print(aCal["id"], aCal["summary"])
if aCal["summary"] == "jReminders":
reminderCalendarId = aCal["id"]
break
assert reminderCalendarId
print('Got jReminders calendar id', reminderCalendarId)
baseListRequest = {
"1": { "4": calendarVersion},
"2": [{"1":3},{"1":16},{"1":1},{"1":8},{"1":11},{"1":5},{"1":6},{"1":13},{"1":4},{"1":12},{"1":7},{"1":17}],
# 3: due_before_ms
# 4: due_after_ms
"5": 0, # include_archived Reminder status (0: Incomplete only / 1: including completion)
"6": 20, # max_results limit
# 7: continuation_token
# 9: include_completed
# 10: include_deleted
# 12: recurrence_id
# 13: recurrence_options
# 14: continuation
# 15: exclude_due_before_ms
# 16: exclude_due_after_ms
# 18: require_snoozed
# 19: require_included_in_bigtop
# 20: include_email_reminders
# 21: project_id
# 22: require_excluded_in_bigtop
# 23: raw_query
#"24" archived_before_ms
#"25" archived_after_ms
# 26: exclude_archived_before_ms
# 27: exclude_archived_after_ms
# 28: utc_due_before_ms
# 29: utc_due_after_ms
# 30: exclude_utc_due_before_ms
# 31: exclude_utc_due_after_ms
# 32: skip_storage_read_parameters
}
#print(content)
# "1"."2": reinder id
# 2: maybe what app created it?
# 3: reminder text
# yr month day 24hr min sec? unix ms
# 5: reminder snooze expired time : {"1":2019,"2":3,"3":16,"4":{"1":14,"2":6,"3":0},"7":"1552759560000"}
# 8: done=1 ?
# 10: 1 (deleted?)
# 11: done time?
# 13: ?
# 16: something about repeat frequency?
# 17: extra bonus info?
# 18: creation ms
# 23: time ms right before creation
# 26: last modified?
print('Getting past reminders')
pastListRequest = copy.deepcopy(baseListRequest)
pastListRequest["16"] = str(int(time.time()) + 0 * 24 * 3600) + "000" # time msec
response, content = auth_http.request(
uri='https://reminders-pa.clients6.google.com/v1internalOP/reminders/list',
method='POST',
body=json.dumps(pastListRequest),
headers=reminderHeaders,
)
assert response.status == 200, (response, content)
obj = json.loads(content)
reminders = obj["1"] if "1" in obj else []
for aReminder in reminders:
aReminderId = aReminder["1"]["2"]
print(time.strftime('%Y-%m-%d', time.localtime(int(aReminder["18"])/1000)), aReminderId, aReminder["3"])
print(aReminder)
# Reminder is not marked done
assert "8" not in aReminder
assert "11" not in aReminder
#assert aReminder["2"]["1"] == 1 # reminder is created in inbox. Otherwise, unsure if delete will work
isRepeat = "16" in aReminder
if '5' in aReminder:
rTime = aReminder["5"]["7"]
assert rTime and len(rTime) > 6
assert re.match(r'^[0-9]+$', rTime)
rTime = int(rTime) / 1000
isPast = time.time() > rTime
else:
rTime = int(aReminder['18']) / 1000
assert rTime > 1000000
isPast = time.time() > rTime
assert isPast
x = input('return to email ["n" to skip]')
if x != 'n':
message = MIMEText(aReminder["3"])
message['To'] = email
message['From'] = email
message['Subject'] = aReminder["3"]
#print (message.as_string())
data = {'raw': base64.urlsafe_b64encode(bytearray(message.as_string(), 'utf-8')).decode('utf-8')}
#print (data)
data["labelIds"] = [ "UNREAD", "INBOX", jreminderLabelId ]
response, content = auth_http.request(
#uri='https://www.googleapis.com/gmail/v1/users/me/messages/send',
uri='https://content.googleapis.com/gmail/v1/users/me/messages?alt=json',
method='POST',
body=json.dumps(data),
headers={'content-type': 'application/json'},
)
assert response.status == 200, (response, content)
x = input('return to delete ["n" to skip]')
if x != 'n':
deleteRequest = {"1":{"4": calendarVersion},
"2":[{"2": aReminderId}]}
response, content = auth_http.request(
uri='https://reminders-pa.clients6.google.com/v1internalOP/reminders/delete',
method='POST',
body=json.dumps(deleteRequest),
headers=reminderHeaders,
)
assert response.status == 200, (response, content)
printReminder(auth_http, aReminderId)
print('Getting future reminders')
futureListRequest = copy.deepcopy(baseListRequest)
#futureListRequest["15"] = str(int(time.time()) + 3 * 365 * 24 * 3600) + "000" # time msec
futureListRequest["16"] = str(int(time.time()) + 30 * 365 * 24 * 3600) + "000" # time msec
response, content = auth_http.request(
uri='https://reminders-pa.clients6.google.com/v1internalOP/reminders/list',
method='POST',
body=json.dumps(futureListRequest),
headers=reminderHeaders,
)
assert response.status == 200, (response, content)
obj = json.loads(content)
reminders = obj["1"] if "1" in obj else []
#print(obj)
for aReminder in reminders:
aReminderId = aReminder["1"]["2"]
print(time.strftime('%Y-%m-%d', time.localtime(int(aReminder["18"])/1000)), aReminderId, aReminder["3"])
print(aReminder)
# Reminder is not marked done
assert "8" not in aReminder
assert "11" not in aReminder
#assert aReminder["2"]["1"] == 1 # reminder is created in inbox. Otherwise, unsure if delete will work
isRepeat = "16" in aReminder
if '7' in aReminder['5']:
rTime = aReminder["5"]["7"]
assert rTime and len(rTime) > 6
assert re.match(r'^[0-9]+$', rTime)
rTimeSecs = int(rTime) / 1000
isPast = time.time() > rTimeSecs
assert not isPast
eTime = datetime.datetime.fromtimestamp(rTimeSecs, dateutil.tz.gettz('America/New_York'))
else:
print('Warning, missing unix timestamp, double check date')
eTime = datetime.datetime(aReminder['5']['1'], aReminder['5']['2'], aReminder['5']['3'],
aReminder['5']['4']['1'], aReminder['5']['4']['2'], aReminder['5']['4']['3'],
tzinfo = dateutil.tz.gettz('America/New_York'))
#nowT = datetime.now().astimezone().isoformat(timespec='seconds')
request = {
'start' : {
'dateTime': (eTime).isoformat(timespec='seconds'),
'timeZone': 'America/New_York',
},
'end' : {
'dateTime': (eTime + datetime.timedelta(minutes=15)).isoformat(timespec='seconds'),
'timeZone': 'America/New_York',
},
'description': aReminder["3"], # detailed description
'summary': aReminder["3"], # top line name of event
'reminders': {
'overrides': [ { 'method': 'email', 'minutes': 5 } ],
'useDefault': False
}
}
if isRepeat:
ruleTxt = 'RRULE:'
repeatInfo = aReminder['16']['1']
assert aReminder['5']['4']['1'] == repeatInfo['5']['1']['1']
assert aReminder['5']['4']['2'] == repeatInfo['5']['1']['2']
assert aReminder['5']['4']['3'] == repeatInfo['5']['1']['3']
# time zone issue maybe
#assert eTime.hour == repeatInfo['5']['1']['1'], (eTime.hour, repeatInfo['5']['1']['1'])
assert eTime.minute == repeatInfo['5']['1']['2']
assert eTime.second == repeatInfo['5']['1']['3']
if repeatInfo['1'] == 3:
ruleTxt += 'FREQ=YEARLY'
elif repeatInfo['1'] == 2:
ruleTxt += 'FREQ=MONTHLY'
elif repeatInfo['1'] == 1:
ruleTxt += 'FREQ=WEEKLY'
elif repeatInfo['1'] == 0:
ruleTxt += 'FREQ=DAILY'
else:
assert False
if '2' in repeatInfo:
ruleTxt += ';INTERVAL=' + str(repeatInfo['2'])
if '7' in repeatInfo:
assert repeatInfo['1'] == 2 # monthly
day = repeatInfo['7']['1'][0]
assert day > 0 and day <= 28
ruleTxt += ';BYMONTHDAY=' + str(day)
if '6' in repeatInfo:
assert repeatInfo['1'] == 1 # weekly
weekday = repeatInfo['6']['1'][0]
assert weekday > 0 and weekday < 7
ruleTxt += ';WKST=MO;BYDAY=' + ['MO','TU','WE','TH','FR','SA','SU'][weekday - 1]
if '8' in repeatInfo:
assert repeatInfo['1'] == 3 # yearly
request['recurrence'] = [ ruleTxt ] # [ 'RRULE:FREQ=DAILY;INTERVAL=3' ]
#nowT = datetime.datetime.now()
#nowT = datetime.datetime(nowT.year, nowT.month, nowT.day, 9, 0, 0)
print(request)
x = input('Create calendar event ["n" to skip]')
if x != 'n':
response, content = auth_http.request(
uri='https://www.googleapis.com/calendar/v3/calendars/' + reminderCalendarId + '/events',
method='POST',
body=json.dumps(request),
headers={'content-type': 'application/json'},
)
assert response.status == 200, (response, content)
print('Created calendar event: ', json.loads(content)['htmlLink'])
if isRepeat:
mm = re.match(r'^([^/]+)/([0-9]+)$', aReminderId)
assert mm
aReminderId = mm.group(1)
subId = aReminder['5']['7']
assert len(subId) > 6
delUrl = 'https://reminders-pa.clients6.google.com/v1internalOP/reminders/recurrence/delete'
deleteRequest = {"1":{"4": calendarVersion},
"2":{"1": aReminderId},
"4":{ "1":1, "2": 0, "3": subId }
}
else:
delUrl = 'https://reminders-pa.clients6.google.com/v1internalOP/reminders/delete'
deleteRequest = {"1":{"4": calendarVersion},
"2":[{"2": aReminderId}]}
print(deleteRequest)
#print(json.dumps(deleteRequest))
x = input('Delete future reminder')
response, content = auth_http.request(
uri=delUrl,
method='POST',
body=json.dumps(deleteRequest),
headers=reminderHeaders,
)
assert response.status == 200, (response, content)
if __name__ == '__main__':
main()














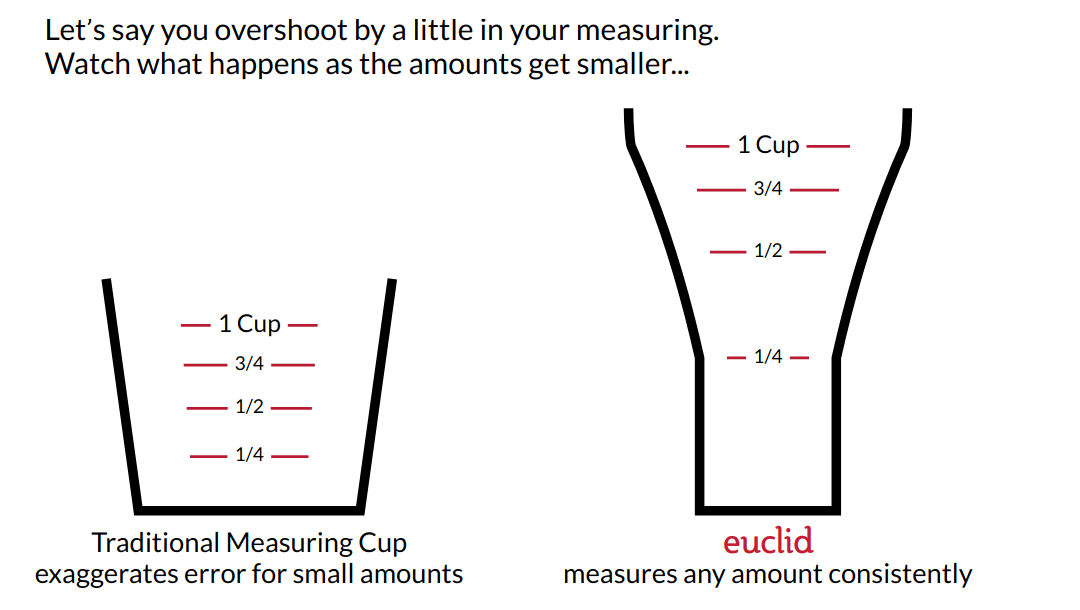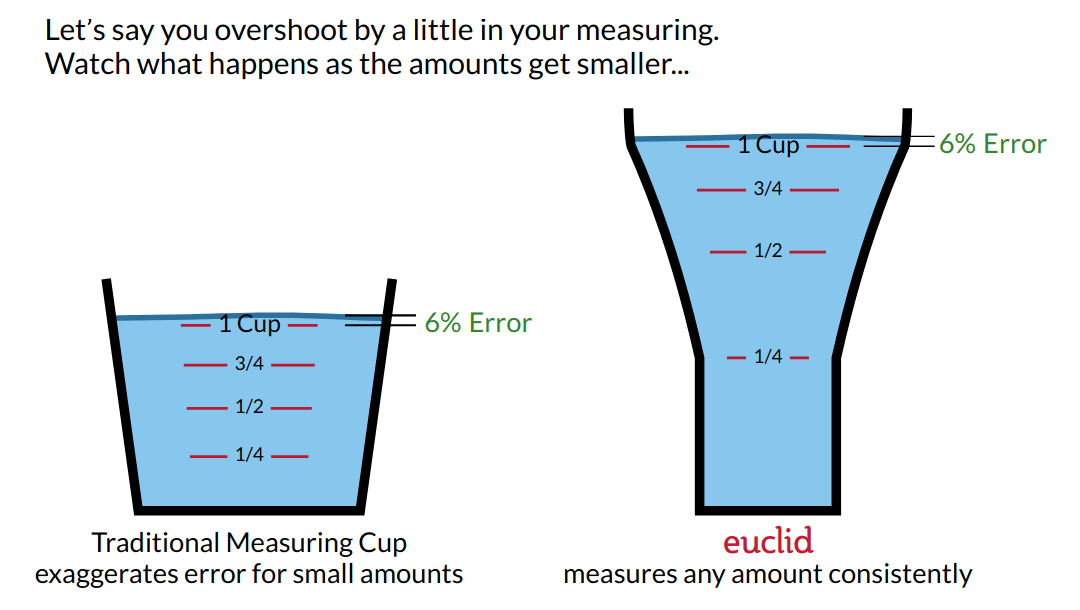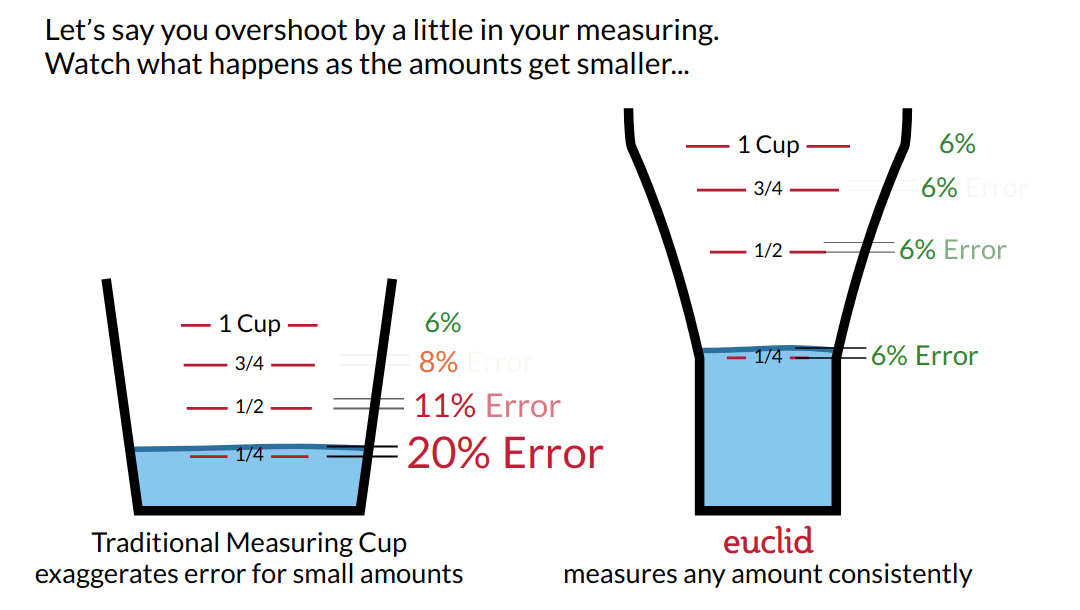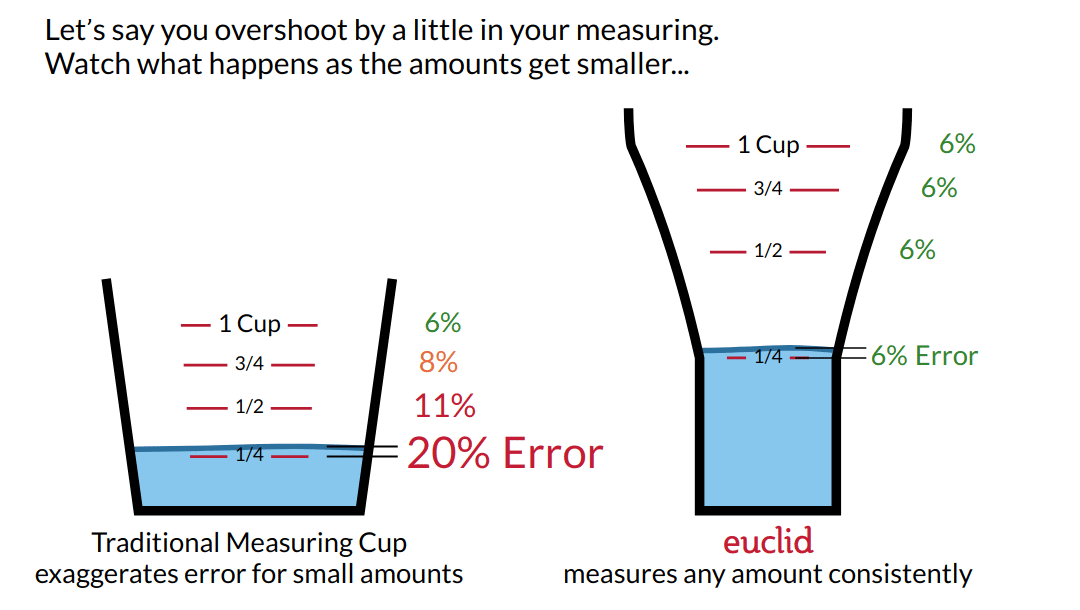

 ----->
----->